Algoritmos de trocas de páginas
Os algoritmos de trocas de páginas são políticas definidas para escolher quais páginas da memória dará lugar à página que foi solicitada e que precisa ser carregada. Isso é necessário quando não há espaço disponível para armazenar a nova página.
O sistema operacional deverá escolher, entre as páginas que estão na memória principal, uma para remover e permitir que a nova página seja trazida para a memória. Se esta página a ser removida foi modificada enquanto estava na memória, ela deverá ser salva no disco antes de poder trazer a nova página. Caso uma página que é freqüentemente acessada seja removida da memória, muito provavelmente ela deverá ser trazida de volta a memória em um curto período, causando um gasto de tempo evitável.
Para gerenciar a memória, e evitar que páginas freqüentemente acessadas sejam removidas da memória, são utilizados os algoritmos de troca de página.
Esses algoritmos que tratam dos problemas de trocas de páginas são aqueles que implementam as estratégias de substituição (replacement strategies) e são denominados algoritmos de troca ou algoritmos de substituição de páginas.
Neles podemos destacar os algoritmos Random, First In First Out, Second Chance, Clock, Clock 2, Last Recently Used (LRU), Last Frequently Used (LFU), Not Recently Used (NRU).
O Algoritmo de troca de páginas Random Page Replacement é um algoritmo de baixa sobrecarga que seleciona aleatoriamente a página que deverá ser substituída.
Suas chances de sucesso são maiores quando há um maior número de páginas existentes. É um algoritmo rápido e de implementação simples, mas é raramente utilizado, pois a página a ser substituída pode ser a próxima a ser necessária.
O First In First Out (FIFO) é um algoritmo que tem como idéia central que as páginas que estão há mais tempo na memória podem ser substituídas, ou seja, as primeiras que entram são as primeiras que saem. Para isto associa se um timepstamp (Marca de tempo), que cria uma lista de páginas por idade, ou seja, por entrada. Cada nova página trazida à memória é colocada no final de uma lista ligada. Ao ocorrer uma falta de página, a página que estiver no começo desta lista será removida. Embora esse algoritmo seja provável e lógico não necessariamente é correto, pois páginas há mais tempo na memória podem ser usadas com muita freqüência. Assim ele não é utilizado da forma pura, mas sim com suas variações.
O Second Chance (Segunda Chance) é uma variação da estratégia FIFO. Como a deficiência do FIFO é que uma página de longa duração e de uso intenso pode ser indevidamente substituída. O algoritmo de troca de páginas segunda chance escolhe a página mais antiga, porém antes de fazer a substituição verifica o bit de referência da mesma. Se o bit estiver em 1, significa que a página foi usada, assim o algoritmo troca sua marca de tempo (timepstamp) e ajusta o bit de referência para zero, simulando uma nova página na memória. Ele fornece uma “segunda chance” para as às páginas antigas de permanecerem na memória primaria.
Basicamente, esse algoritmo trabalha fazendo com que as páginas fiquem em uma lista onde no início se encontram as páginas mais velhas que se após a verificação constatar que a página foi usada será reposicionada para o final (mais novas).
O algoritmo de troca de páginas Clock (relógio) é outra variação da estratégia FIFO. Enquanto o algoritmo de troca de páginas FIFO substitui uma página em função de sua idade na memória e o algoritmo second chance verifica o bit mantendo na memória páginas de uso intenso através da renovação de seu timestamp. O clock mantém uma lista circular, onde se o bit de referência é 1 o seu valor é trocado por zero, e a referência da lista é movida conforme os ponteiros de um relógio, caso contrario a página será substituída.


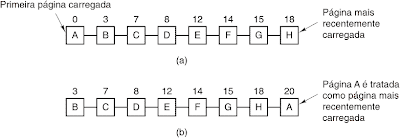
O algoritmo de troca de paginas LRU (least Recently Used ou menos usada recentemente) tem como funcionalidade identificar a página menos utiliza por mais período de tempo.
É necessário que cada página possua o timestamp. Ele tem como idéia que as páginas usadas recentemente logo não serão usadas e retira da memória a página que há mais tempo não é utilizada.
A implementação ocorre através de listas, sendo que a página mais recentemente usada se localiza no início da lista e a menos usada no final. É necessário atualizar a lista a cada referência à memória.
Sua deficiência ocorre em laços longos ou chamados com muitos níveis de profundidade, pois a próxima pagina a ser usada pode ser uma das menos usadas recentemente.
O Least Frequently Used – LFU (Menos usada frequentemente) ou Not Frequently Used – NFU (Não usada frequentemente) são algoritmos de estratégia para o LRU, que calcula a freqüência de uso das páginas de forma a identificar qual página foi menos intensivamente utilizada. Sua deficiência é que ainda é possível páginas pesadas que foram utilizadas durante uma certa etapa do processamento permaneçam sem necessidade na memória primária em relação a outras etapas mais curtas, cujas páginas não terão uso tão intenso, levando a substituições inúteis.
O algoritmo NRU (Not Recently Used) tem como idéia escolher a página que está há mais tempo sem uso para efetuar a troca, sendo que a página mais recente é excluída da decisão e através do método FIFO, é feita a escolha dentre as outras de qual página deve sair. Este algoritmo é utilizado em vários sistemas devido sua forma simples, de fácil implementação e desempenho adequado.
Exemplos de S.O
No Linux, a memória funciona com prioridade para processos que estão em execução. Quando um processo termina, havendo espaço na memória, o sistema mantém resíduos desse processo na memória para que uma possível volta a processo seja mais rápida. Caso essa memória RAM esteja lotada com processos que estão em execução, aí se faz uso da memória SWAP (troca).
O sistema operacional MS Windows 95 utiliza a estratégia de substituição de páginas LRU (least recently used ou menos usada recentemente).

